
TL;DR:
- Most organizations underestimate the extensive sociotechnical work required to deploy agentic AI effectively in production.
- Successful deployment demands organizational readiness, careful architecture decisions, staged rollout, and robust monitoring to prevent failure.
Most organizations underestimate what it actually takes to deploy agentic AI in production. The models work. The demos look convincing. But then the real work begins. According to MIT Sloan research, more than 80% of AI agent deployment effort is sociotechnical work tied to infrastructure, governance, and organizational change, not prompt engineering. This agentic AI deployment guide gives business leaders and operations managers a structured path through that complexity. From organizational readiness to production rollout to post-deployment monitoring, every stage is covered with specificity.
Table of Contents
- Key takeaways
- Agentic AI deployment guide: organizational readiness first
- Steps to deploy AI agents in production
- Monitoring and operating AI agents at scale
- Common pitfalls in agentic AI deployments
- My take on what actually separates successful deployments
- Ready to deploy agentic AI with confidence?
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Sociotechnical work dominates | Most deployment effort goes to data pipelines, governance, and change management, not model configuration. |
| Proximity and reversibility matter | Align your deployment pace with where agents sit in the customer journey and how easily errors can be undone. |
| Architecture choices are permanent | Stateful vs. event-driven design decisions made early will define your operational ceiling for years. |
| Staged rollout reduces risk | A canary approach with a 48-hour monitoring window before full traffic migration catches failures early. |
| Observability must come first | Distributed tracing and audit logging are non-negotiable for diagnosing multi-step agent failures in production. |
Agentic AI deployment guide: organizational readiness first
Before a single line of agent code runs in production, your organization needs to pass a readiness check that most teams skip. That skip is what causes expensive failures six months later.
Data pipelines and integration infrastructure
Agentic AI systems need real-time or near-real-time access to business data. Your CRM, ERP, document management platform, and scheduling systems must expose clean, accessible APIs. Agents that operate on stale or inconsistent data make bad decisions at scale. Before deployment, audit every data source the agent will touch and confirm that access is reliable, permissioned, and monitored.

Governance and compliance deserve equal weight with technical infrastructure. Data pipelines and governance should be treated as first-class workstreams alongside AI development, not afterthoughts. That means assigning ownership, defining data retention rules, and documenting how the agent handles personally identifiable information before go-live. Organizations operating in regulated industries will want to review AI compliance requirements specific to their sector before architecture decisions are finalized.
Proximity and reversibility as a planning framework
Yale Insights recommends aligning deployment pace and governance intensity with two variables: how close the agent operates to the customer, and how reversible its actions are. An agent that drafts internal meeting summaries sits far from the customer and its errors are easy to correct. An agent that sends client-facing emails or initiates payment transactions is close to the customer and its errors may be irreversible.
Use this framework to decide which workflows to automate first and how much human oversight each one requires:
- Low proximity, high reversibility: Automate freely, monitor lightly. Examples include internal document classification and calendar coordination.
- Low proximity, low reversibility: Automate with approval gates. Examples include updating financial records or deleting archived files.
- High proximity, high reversibility: Automate with monitoring. Examples include sending draft responses for human review before delivery.
- High proximity, low reversibility: Automate only with confirmed human-in-the-loop controls. Examples include customer refund processing or contract execution.
Change management rounds out organizational readiness. Staff need to understand what the agent does, where it hands off to humans, and how to flag unexpected behavior. Without that alignment, agents get bypassed or misused.
Pro Tip: Map every intended workflow to a proximity/reversibility quadrant before writing your AI deployment checklist. This single step will clarify governance requirements faster than any framework meeting.
Steps to deploy AI agents in production
With organizational readiness confirmed, the technical deployment follows a defined sequence. Skipping stages does not save time. It relocates problems to production.
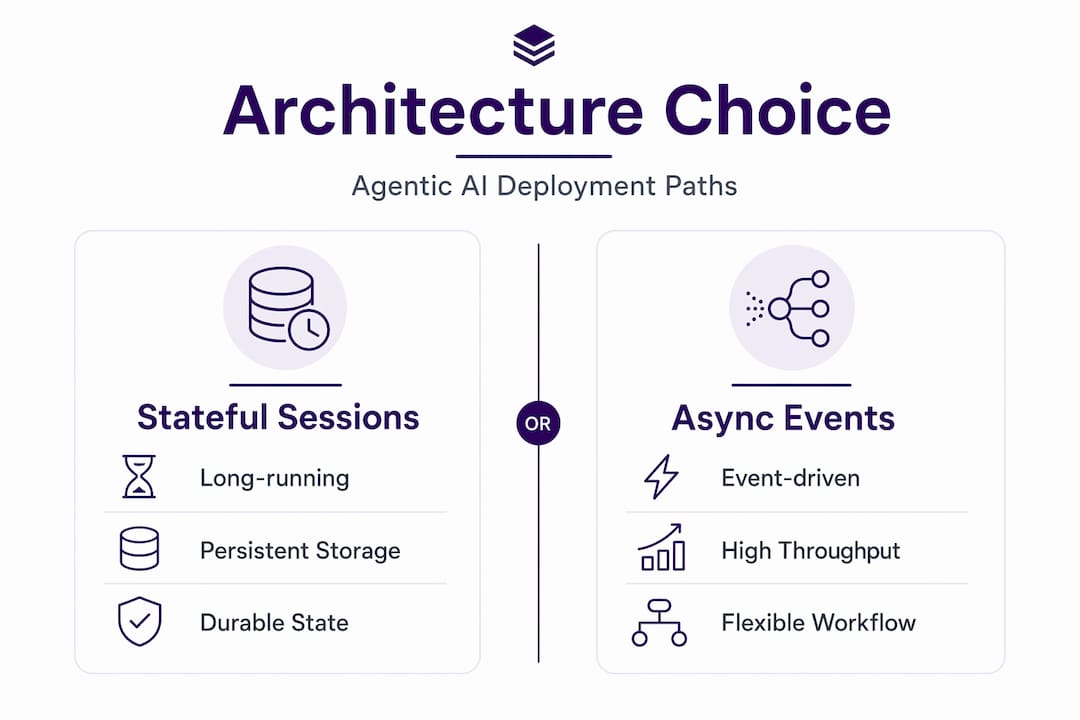
Choosing your architecture
The first decision is whether your agents need stateful session management or event-driven asynchronous processing. Stateful agents hold context across a conversation or task session. They work well for short workflows where a user interacts continuously. Event-driven agents pause between steps, persist their state, and resume when triggered by a webhook or scheduled event. They scale better for long-running business workflows like invoice approval chains or multi-day onboarding sequences.
For long-running processes, durable state machines with persistent session storage are the correct pattern. Google’s Agent Development Kit demonstrates this with SQLite or Cloud SQL backed runtimes that allow an agent to pause mid-task and resume without losing context. This matters operationally because event-driven dormancy with webhook-driven resumption is what makes compute scaling viable. You are not paying for idle runtime between steps.
Multi-agent delegation
Complex business workflows are better handled by a coordinator agent that delegates subtasks to specialized agents. One agent handles document extraction, another handles CRM updates, a third handles notification dispatch. This modular design makes testing easier, failure isolation cleaner, and upgrades less disruptive. It also mirrors how real teams divide work, which makes the system easier for operations staff to understand and audit.
Deployment stages
Follow this sequence without shortcutting:
- Scaffold and configure locally. Use your chosen agentic AI framework CLI to scaffold the agent, configure tool connections, and define initial behavior policies.
- Run golden evaluations. Create a set of test cases with known correct outputs. Run the agent against these before any live traffic.
- Deploy to staging with shadow mode. Route real requests to the agent without acting on its outputs. Compare its decisions against current human decisions to calibrate accuracy.
- Canary release to production. Route 5% of live traffic through the agent. Monitor for 48 hours before expanding.
- Graduated rollout. Expand traffic in stages: 10%, 25%, 50%, 100%. Validate key metrics at each gate before proceeding.
| Deployment stage | Traffic volume | Key validation |
|---|---|---|
| Golden evaluation | 0% (synthetic) | Output accuracy vs. known results |
| Shadow mode | 100% (read-only) | Decision alignment with human baseline |
| Canary | 5% | Error rate, latency, cost per task |
| Graduated rollout | 10% → 100% | Escalation rate, user feedback, cost |
Pro Tip: Build your golden evaluation set from real historical cases, not invented scenarios. Real cases surface edge cases that invented ones miss, especially in billing and compliance workflows.
Monitoring and operating AI agents at scale
Deployment is not the finish line. Production operations require a structured approach to observability, cost, and security. The teams that treat monitoring as an afterthought are the ones that discover failures through customer complaints.
The five-layer operations stack
Organize your production operations around these five layers:
- Compute: Container orchestration, autoscaling policies, and resource limits per agent instance.
- State management: Persistent session stores with TTL policies and checkpoint frequency settings. Checkpoint-resume infrastructure can reduce token usage by up to 40% during degraded conditions by avoiding full workflow restarts.
- Observability: End-to-end distributed tracing across every tool call and agent handoff. Distributed tracing is critical because multi-step agent failures are rarely reproducible on demand.
- Cost controls: Per-task token budgets, model tiering by reasoning complexity, and semantic caching for repeated query patterns. Semantic caching and tiered model usage are proven techniques for controlling cost and latency in multi-step workflows.
- Security boundaries: Scoped API permissions, no shared credentials across agents, and confirmation gates before any irreversible action. Scoped permissions and confirmation gates prevent overly broad access from causing destructive errors.
Security and governance in production
AI governance in deployment does not end at launch. Every agent operating on live business data needs a permission scope limited to its specific function. An agent managing scheduling should not have write access to financial records. Access reviews should run on a regular cycle, not just at initial deployment.
For actions that cannot be undone, such as sending a signed contract or initiating a bank transfer, explicit human-in-the-loop gates are mandatory before execution. This is not a performance limitation. It is how you maintain governance compliance at scale. Ailerons covers this design principle in depth in their secure AI deployment guide for business leaders.
Pro Tip: Set token budget alerts at 70% of your per-task limit, not 100%. Alerts at the ceiling give you zero time to intervene before cost overruns compound.
Common pitfalls in agentic AI deployments
Optimizing AI deployment means understanding what breaks most often. The causes are predictable, and most of them have nothing to do with the underlying model.
Operational complexity, not model quality, is the leading cause of production agent failures. That finding consistently surprises teams who spend months selecting the right model and hours thinking about infrastructure. The gap is almost always organizational.
Here are the failure patterns worth preparing for:
- Tool call failures without graceful handling. Agents that receive an error from an external API and have no fallback path will stall or loop. Build typed error responses with retry limits into every tool integration, and define what the agent does when retries are exhausted.
- Context window mismanagement. Long workflows can push an agent past its context window, causing it to lose critical early instructions. Use summarization checkpoints to compress earlier steps and preserve decision-relevant context.
- Prompt injection via external content. Agents that process user-supplied documents or emails are vulnerable to adversarial instructions embedded in that content. Validate and sanitize all external input before it enters the agent’s context.
- Latency and cost blowouts. Agents that use a large reasoning model for every step, including trivial ones, will exceed cost targets quickly. Route simple steps to smaller, faster models and reserve the large model for reasoning-intensive decisions.
- Scope creep in permissions. Agents accumulate access over time as teams add capabilities. Audit tool permissions at least quarterly and remove anything not actively used.
Pro Tip: Add iteration limits to every agentic loop at the architecture level, not the prompt level. Prompt-level limits can be overridden by the model’s reasoning. Hard iteration caps in code cannot.
My take on what actually separates successful deployments
I’ve reviewed a significant number of agentic AI deployments across office operations, finance, and administrative functions. The technology almost never fails on its own terms. What fails is the organizational work surrounding it.
The teams that succeed treat data governance and change management with the same rigor as their technical architecture. They assign named owners to every integration, document escalation paths before launch, and run tabletop exercises against failure scenarios. They build observability before functionality. If you cannot see what the agent is doing step by step, you cannot trust it in production, no matter how well it performs in staging.
The proximity and reversibility framework from Yale Insights is one of the more useful tools I’ve encountered for aligning leadership on deployment sequencing. It converts an abstract risk conversation into a concrete prioritization decision. Executives understand it immediately.
My honest read: organizations that rush agentic AI into high-stakes, irreversible workflows without completing the readiness work described above will have a failure that sets their program back 12 to 18 months. The ones that pace deployment according to risk and build operational discipline from day one will compound returns quietly while others are still troubleshooting. Ailerons has published additional thinking on AI trends for 2026 that reflects this same operational discipline across industries.
The heaviest lift is not the model. It is the organization.
— Sam
Ready to deploy agentic AI with confidence?
Ailerons designs and deploys agentic AI systems for business operations, from initial readiness assessment through production monitoring and governance. Whether your priority is document management, billing automation, front-office coordination, or compliance-driven workflows, the team at Ailerons builds systems that integrate with your existing platforms and operate within defined security boundaries.
You can review how Ailerons has implemented agentic AI for clients across office operations and see documented outcomes before committing to a direction. For a closer look at the full range of services and how they map to your specific workflow needs, visit Ailerons IT consulting services or book a consultation to discuss a deployment plan tailored to your organization’s risk profile and operational goals.
FAQ
What is an agentic AI deployment guide?
An agentic AI deployment guide is a structured framework that walks business leaders through preparing, launching, and operating AI agents in production. It covers organizational readiness, architecture choices, staged rollout, and ongoing monitoring.
How long does it take to deploy agentic AI for businesses?
Timeline depends on workflow complexity and data infrastructure maturity. A well-prepared organization can reach canary deployment in six to twelve weeks, but full production stability across multiple workflows typically takes three to six months.
What is the biggest risk in agentic AI deployment?
Operational complexity and governance gaps cause more production failures than model quality issues. Inadequate observability, overly broad permissions, and missing escalation paths are the most common failure points.
What agentic AI frameworks are commonly used in production?
Popular agentic AI frameworks include Google’s Agent Development Kit, LangGraph, and AutoGen. Framework choice depends on whether your workflows require stateful session management, multi-agent coordination, or event-driven long-running task handling.
How do you control cost when running AI agents at scale?
Use token budgets per task, route simpler reasoning steps to smaller models, and implement semantic caching for repeated query patterns. Tiered model usage and semantic caching are the two most effective techniques for keeping cost and latency within target ranges in multi-step agentic workflows.
Recommended
- What is secure AI deployment: A guide for business leaders | Ailerons
- Step by Step Business Automation Guide for SMBs | Ailerons IT Consulting
- Step-by-Step Guide to AI-Driven Office Automation Success | Ailerons IT Consulting
- AI in Business Process Management: Unlocking Efficiency | Ailerons IT Consulting